
作者 | 路一直都在
出品 | AI科技大本营(ID:rgznai100)
Paper link:https://arxiv.org/pdf/1904.02701.pdfCode link:https://github.com/OceanPang/Libra_R-CNN
Abstract
在目标检测中,人们更关注的往往是模型结构,而在训练过程中投入的注意力相对较少。但是训练过程对于一个目标检测器来说同样关键。在本工作中,作者仔细回顾了检测器的标准训练过程,发现在训练过程中,检测性能往往受到不平衡的限制。这种不平衡往往包括三个方面:sample level(样本层面),feature level(特征层面),objective level(训练目标层面),为了上述三个不平衡对检测性能的影响,本文提出了Libra R-CNN,一个针对目标检测平衡学习的简单有效框架。该框架集成了三个组件:IoU-balanced sampling,balanced feature pyramid,balanced L1 loss,分别对应解决上述的三个不平衡。基于这些改造,Libra R-CNN在AP上的提升有两个多点,可以说是简洁高效。
Introduction
随着深度卷积神经网络的发展,目标检测任务取得了很大的突破。Faster R-CNN,RetinaNet,Cascade R-CNN是其中的代表性框架。不论是one-stage结构还是two-stage结构,主流检测框架大都遵循一种常见的训练范式,即对区域进行采样,从中提取特征,然后在一个标准的多任务目标函数的指导下,共同进行分类和细化位置任务。基于这种指导思想,目标检测训练的成功取决于三个关键方面:(1)选取的区域是否具有代表性(2)提取的特征是否被充分利用到(3)目标损失函数是否是最优的。
作者研究发现,现有的目标检测网络在三个方面都存在严重的不平衡。这种不平衡阻碍了网络架构发挥最佳性能,进而影响了整个检测器的效果。下面介绍一下这三个不平衡,如下图所示:
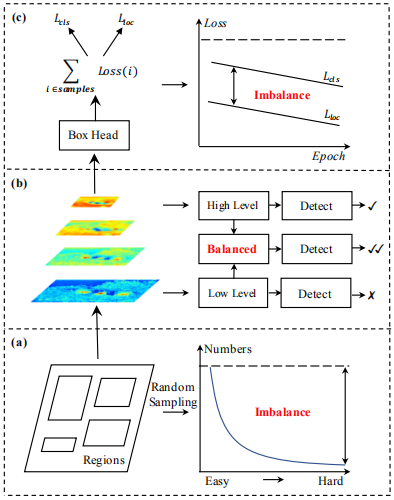
(a)Sample level imbalance:
当训练一个目标检测器时,对于hard samples的训练更有利于提升检测器的表现,如果把训练中心放在easy samples,整个训练结果会被带偏。基于随机采样机制进行区域选取,造成的结果一般是使挑选的样本趋向于easy类型,为了解决这个问题,有著名的OHEM,能够更多的关注hard samples,但是它们通常对噪音很敏感,并会产生相当大的内存和计算成本;RetinaNet中提出了著名的损失函数Focal loss,应用于one-stage的效果较好,但是,扩展到大部分样本为简单负样本的two-stage模型中,效果一般。(b)Feature level imbalance我们知道,底层特征拥有高分辨率信息,随着卷积层数的加深,高层特征拥有更丰富的语义信息。把高分辨率信息和丰富的语义信息结合能显著增强特征表达,FPN,PANet都是这方面的成功案例。这些网络结构给我们的启发是可以通过将底层特征信息和高层特征信息互补应用于目标检测。如何利用它们来整合金字塔特征表示的方法决定了检测性能,那么这就引申出一个问题:将不同层特征组合在一起的最佳方法是什么?作者实验表明,组合后的特征必须从各分辨率特征中进行均衡。但是上述方法中的顺序方式将使组合特征更多地关注相邻分辨率,而较少关注其他分辨率,每融合一次,非相邻层中包含的语义信息将被稀释一次。(c)Objective level imbalance一个目标检测器需要完成两个任务,目标分类和定位,因此总的训练目标是两个任务目标的结合,这可以看做是一个multi-task的训练优化问题,如何给不同任务赋予权重,保持各个任务之间的平衡,将决定最后的效果。此情形同样适用于训练过程中的样本,如果不平衡,由简单样本产生的小梯度值会淹没困难样本产生的较大的梯度值,进而使得训练被简单样本主导,某些任务无法收敛。因此,针对最优收敛,需要平衡相关的任务及样本。 为了减轻这些不平衡造成的影响,本文提出了Libra R-CNN,通过引入IoU-balanced sampling,balanced feature pyramid和balanced L1 loss三个架构组件来解决不平衡问题。Libra R-CNN在COCO上相比Faster R-CNN,RetinaNet AP至少涨了两个点,在简单有高效的框架基础上,更加难能可贵。
Method
下图是整个Libra R-CNN的结构图,作者的目标是使用整体平衡的设计来缓解检测器训练过程中的不平衡,从而尽可能地挖掘模型架构的潜力。
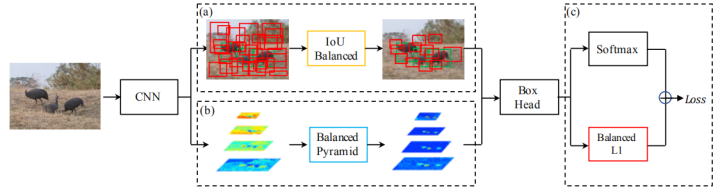
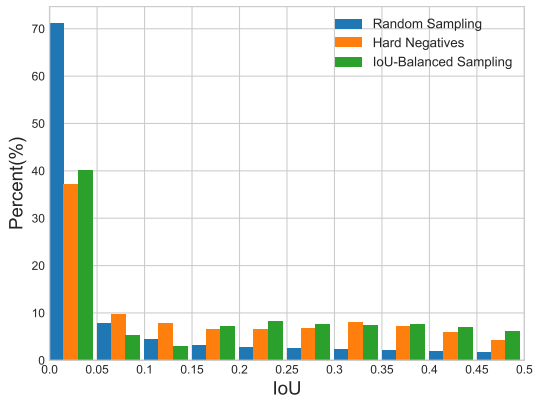
下面来详细介绍一下:1. IoU-balanced Sampling作者首先进行了一个实验,实验的目的是为了验证训练样本与其对应ground-truth之间的重叠是否与其难度相关。也就是说,样本的hard还是easy和对应ground-truth的IoU有没有关系。这里重点看hard negative samples,结果如下图所示,超过60%的hard negative samples的IoU都是大于0.05的,但是在随机抽样中,只有大约30%的样本IoU大于0.05,这种极度的不平衡性导致hard samples被大量的easy samples淹没。
基于实验发现,本文提出了IoU-balanced sampling解决样本之间的不平衡性。具体做法为:假定我们需要从M个候选中抽取N个负样本,每个样本被抽中的概率很好计算:
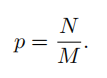
为了增加hard negative samples被抽中的概率,根据IoU将抽样区间平均分成K个格子。N个负样本平均分配到每个格子中,然后均匀地从中选择样本,此时被选中的概率为:
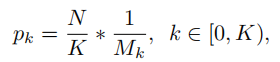
*Mk表示k个对应区间内的抽样候选个数,K在实验中默认为3
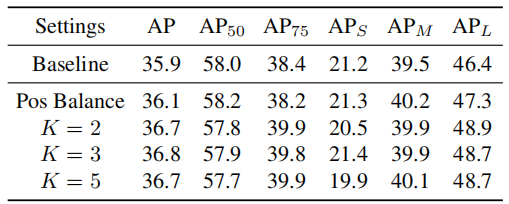
*实际上,作者在实验中证明,K的取值并不敏感,如下图所示,取不同的K值,AP表现差别不大,也就是说,将IoU分为几个区间,并没有那么重要。
这种方法最大的转变是作者通过在IoU上均匀采样, 使得hard negative在IoU上均匀分布。
2. Balanced Feature Pyramid
为了将不同特征层的信息融合,得到高分辨率和高语义信息的表达,FPN等网络结构提出了横向连接(lateral connection),与以往使用横向连接来整合多层次特征的方法不同,本文的核心思想是利用深度整合的均衡语义特征来强化多层次特征。
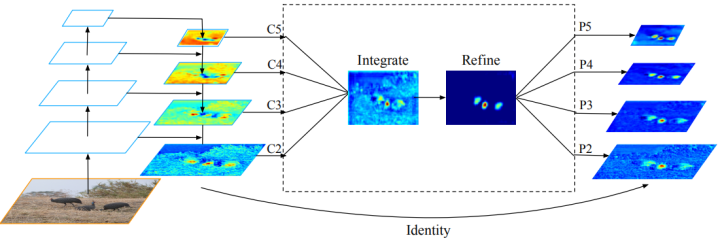
如下图所示,整个过程分为四步,rescaling(尺寸调节),integrating(特征融合),refining(特征细化),strengthening(特征增强)。
Obtaining balanced semantic features
假设C_l表示第l层特征,lmin,lmax分别表示最底层和最高层的特征。如下图所示,C2有最高的分辨率,为了整合多层次的功能,同时保持它们的语义层次。作者首先将不同层的特征{C2,C3,C4,C5 }进行resize,resize到相同的尺寸,如C4。resize的方法无外乎插值和最大池化。尺寸调整完毕后,可以通过下式得到平衡后的语义特征:
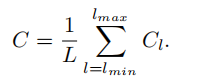
得到的特征C,进行rescale然后通过反向操作增强原始每层的特征,每个分辨率特征从其他分辨率特征中同等的获得信息。此过程不包含任何参数,证明了信息传递的高效性。
Refining balanced semantic features
平衡的语义特征可以进一步细化,使其更具辨别力,作者受《Non-local neural networks》的启发,利用embedded Gaussian non-local attention进行特征细化。通过特征细化能进一步丰富特征信息。
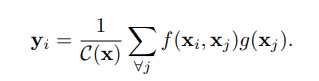
融合后得到的特征{P2,P3,P4,P5}用于后续的目标检测中,流程和FPN相同。
3. Balanced L1 Loss
目标检测的损失函数可以看做是一个多任务的损失函数,分为分类损失和定位损失,可以用下列式子表示:
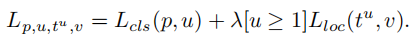
其中,Lcls 和Lloc分别是分类和定位的损失函数。在分类损失函数中,p是预测值,u是真实值, 是类别u的位置回归结果,v是位置回归目标。λ是调整多任务权重参数。在这里定义损失大于等于0.1的样本为outliers,剩余样本为inliers。
为了平衡不同任务,调整参数λ是一个可行的办法。但是,由于回归目标是没有边界限制的,直接增加回归损失的权重将会使模型对outliers更加敏感。对于outliers会被看作是困难样本(hard example),这些困难样本会产生很大的梯度阻碍训练,而inliers被看做是简单样本(easy example)只会产生相比outliers大概0.3倍的梯度。基于此,作者提出了balanced L1 Loss,在下文中用Lb表示。
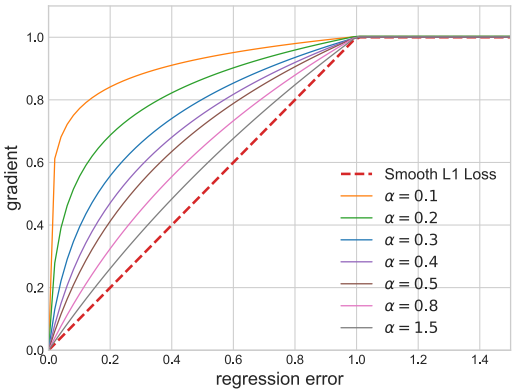
Balanced L1 Loss受smooth L1 Loss的启发,所以这里先贴一个smooth L1 loss的解释:


smooth L1 Loss的思想是,当x较大时,按照一个恒定的速率梯度下降,等到x较小时, 不再按照一个恒定大梯度下降,而是按照自身进行动态调整。
如下图所示,设置一个拐点区分outliers和inliers,对于那些outliers,将梯度固定为1。
Balanced L1 Loss的关键思想是提升关键的回归梯度,即来自inliers的梯度(准确样本),以重新平衡所涉及的样本和任务,从而在分类、整体定位和准确定位方面实现更平衡的训练。
利用balanced L1 Loss的 可以表示为:
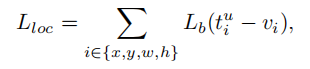
对应的梯度公式如下所示:

基于上述公式,设计了一个提升梯度的公式:
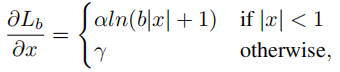
其中,α控制着inliers梯度的提升;一个很小的α会提升inliers的梯度同时不影响outliers的值。γ控制调整回归误差的上界,能够使得不同任务间更加平衡。α,γ从样本和任务层面控制平衡,这两个控制不同方面的因素相互增强,达到更加平衡的训练。
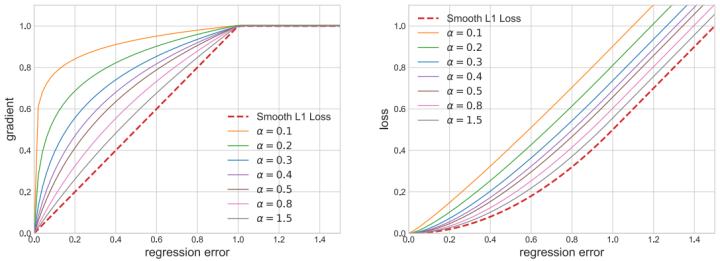
如下图所示,相比smooth l1 loss,本文提出的balanced l1 loss能显著提升inliers点的梯度,进而使这些准确的点能够在训练中扮演更重要的角色。
对梯度公式进行积分,就可以看到Lb也就是Balanced L1 Loss的庐山真面了:
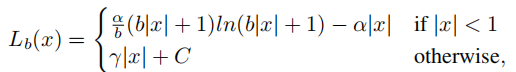
其中,为了保证函数的连续性,在x=1时,需要满足下式:
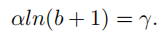
*在本文中,α = 0.5 and γ = 1.5
Experiments
三个组件的效果对比
可以看到,即使单独应用一个组件,总体相比baseline都会有提升,如果将三个都组合起来,AP提升是最大的,充分验证了Libra R-CNN的威力.

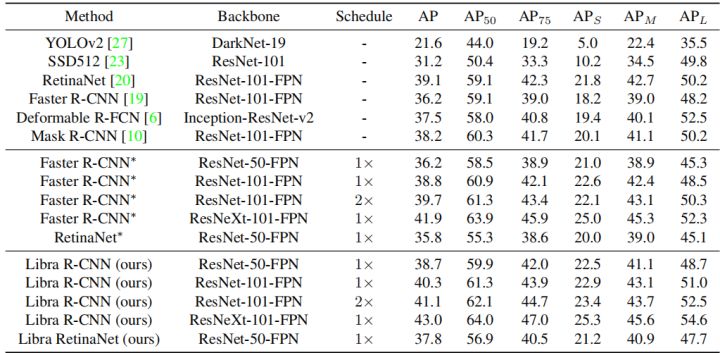
与主流目标检测网络对比
在COCO数据集上,Libra R-CNN在AP上相对主流的one-stage和two-stage方法都有不同程度的提升
Conclusion
本文分析了当前目标检测中存在的三个不平衡问题:
(1)Sample level
(2)Feature level
(3)Objective level
针对这三个不平衡,对症下药,提出了包含三个组件的Libra R-CNN架构,包括:
(1)IoU-balanced Sampling
(2)Balanced Feature Pyramid
(3)Balanced L1 Loss
很好的解决了三个不平衡带来的问题和挑战,使得网络框架能够发挥出更好的性能,COCO数据集上的实验结果表明,Libra R-CNN与最先进的探测器相比,包括one-stage和two-stage框架相比,都获得了显著的改进。

历史文章推荐
不是我们喜新厌旧,而是RAdam确实是好用,新的State of the Art优化器RAdam机器学习中的评价指标CVPR2019 |《胶囊网络(Capsule Networks)综述》,附93页PPT下载AiLearning:一个 GitHub万星的中文机器学习资源深度学习中的数据增强方法总结
Multi-task Learning(Review)多任务学习概述医学图像处理与深度学习入门AI综述专栏 | 多模态机器学习综述深度学习中不得不学的Graph Embedding方法学习率和batchsize如何影响模型的性能?旷视研究院新出8000点人脸关键点,堪比电影级表情捕捉
你正在看吗??


