
本文介绍了一种基于动态元嵌入的中文命名实体识别方法。本项工作由赛博智能团队中的张乃心提出,相关论文已于2019年5月在领域期刊发表录用。
背景介绍
命名实体识别旨在从非结构化文本中识别出特定类别的实体,例如人名、地名、组织机构名等。它是自然语言处理的关键技术之一,同时也是许多自然语言处理高层任务及应用(如:实体链接、关系抽取、事件抽取)的技术基础。
随着互联网的飞速发展,非结构化的文本数据以指数形式不断增长,因此人们对于海量数据的文本挖掘、信息抽取、知识的组织需求也呈现急速增长态势。面对海量的非结构化数据,组织关联的第一步就是对实体的识别获取。但是庞大的数据量使得人工获取实体变得不切实际,命名实体识别的目的就是为了实现对实体的自动化抽取。下图为一个简单的分词示例:

分词示例
目前中文领域命名实体识别方法主要有两大类,基于字以及基于词的方法。但是这两大类方法各有不足:基于字的模型不能获取丰富的词级别的特征信息,而基于词的模型常常会受中文分词结果的影响不能获得好的实验结果。
因此,本文提出一种基于动态元嵌入的模型,通过采用动态融合字、词多粒度特征信息的方式,解决现有方法中存在的信息不完善、过多依赖中文分词等问题。
模型展示
整体结构如下图所示,一共由3层构成,分别为动态元嵌入层、双向LSTM层以及CRF层。其中动态元嵌入层采用了两层注意力机制来融合字、词两个粒度的特征信息;双向LSTM层又由前向网络、后向网络以及拼接层组成,用以学习上下文及深层语义特征;前后向网络隐含层的输出拼接后作为CRF层的输入,通过CRF解码实现序列标注。
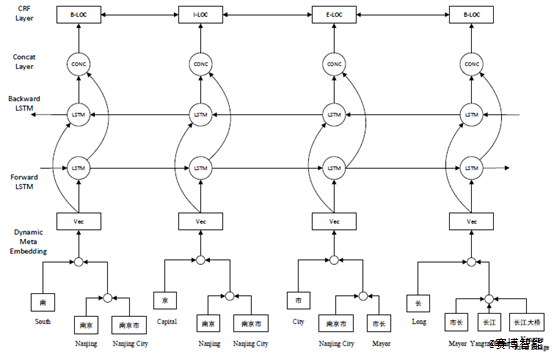
模型整体结构

动态元嵌入层

动态元嵌入层的作用是在embedding层动态地融合字、词多粒度特征信息。多粒度信息融合主要有两个关键问题:一是,针对句子序列中的每个字,其所对应的匹配词如何获取;二是,在拿到该字以及相应的匹配词后,字、词两个粒度的信息如何融合。
针对句子序列中的特定字,选取既在词典中出现又在句子序列中出现的词,作为该字的匹配词。以序列“南京市长江大桥”为例,其中“南”字在词典中可以有很多匹配词,如“南京”、“南昌”、“南方”等等。但在选取匹配词的过程中,不选“南昌”、“南方”,最终的匹配结果是“南京”和“南京市”。因为这两个词不仅与词典匹配又与句子序列匹配,不仅包含了词级别的特征信息又蕴含了句子序列信息。
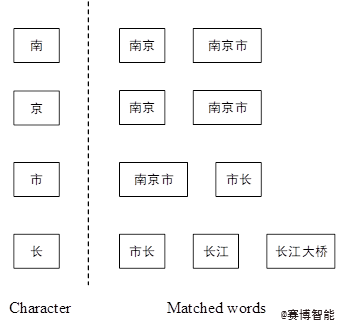
匹配词
在获取该字以及相应的匹配词后,我们采用两层注意力机制来融合字、词两个粒度的特征信息。首先将字、匹配词转化为向量表示(字、词向量维度相同),采用一层注意力机制获取匹配词的词级别总体特征信息,再采用一层注意力机制将字与词级别的特征信息进行融合。
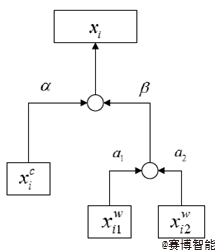
动态元嵌入层细节
融合后的向量即蕴含字、词两粒度特征信息,动态则体现在对于出现在不同句子序列的同一个字,其融合后的向量是不同的。如两个句子序列“南京市长江大桥”与“南昌是个好地方”,它们都含“南”字,但依据本文多粒度信息融合的方法,这两个“南”字最后将会得到两个不同的融合向量。这是由于它们处在不同的序列中,各自对应不同的匹配词。
BiLSTM-CRF结构
动态元嵌入层所得向量作为后续BiLSTM-CRF结构的输入。BiLSTM-CRF结构是目前序列标注任务中最常用也是表现效果较好的结构,由双向LSTM层与CRF层串联组成。
双向LSTM层由三层构成:前向LSTM层、后向LSTM层以及拼接层。其中前向LSTM层中隐含层向量的计算方式为自左向右,在LSTM单元的计算过程中加入了句子序列的上文信息,而后向LSTM层的计算与之相反,它自右向左地将序列信息加入LSTM单元的计算过程中,获取句子序列的下文信息,最后通过拼接层将包含上文与下文信息的隐含层向量进行拼接,作为CRF层的输入。CRF层则对上述向量进行解码,完成序列的预测标注。
模型对比
Character-baseline:实验基准模型,结构最为简单,为单纯的基于字的BiLSTM-CRF模型;
Char+seg-feature:该模型在基准模型的基础上加入部分分词特征,将每个字所对应的分词位置信息映射为固定向量,在embedding层与字向量拼接,作为BiLSTM-CRF的输入。
DEM-SUM:这一模型采用的是基础版的动态元嵌入,匹配词获取后匹配词向量与当前字向量直接按位相加,以此完成字词两粒度的信息融合。
DEM-CONC:与DEM-SUM类似,但在获取匹配词后,匹配词向量与当前字向量采用直接拼接的方式进行融合。
DEM-attention based-conc:与本文详述模型类似,但在词级别整体信息与字向量融合时采用向量拼接的方式。
实验结果
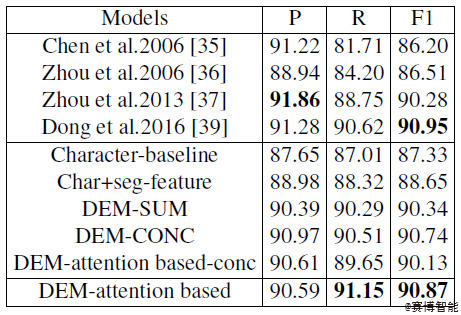
在MSRA以及LiteratureNER数据集上分别进行实验,与其他模型作对比,用本文所提出的模型(DEM-attention based)在这两个数据集上均取得不错结果。
MSRA上实验结果
LiteratureNER上实验结果
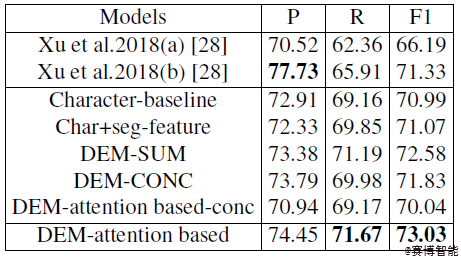
其中,Char+seg-feature的实验结果优于Character-baseline,表明单纯字级别的信息不够完善,在实体识别的过程中加入词级别的信息是十分有必要的。本文所提出的模型在所有模型中表现最佳,与DEM-SUM作比则证明了注意力机制在信息融合过程中发挥着重要的作用,与DEM-attention based-conc作比则体现了按位相加这一计算方式能够更加充分地实现多粒度的信息融合。
参考文献
[1] D. Hu, “An introductory survey on attention mechanisms in NLP problems,” CoRR, vol. abs/1811.05544, 2018.
[2] D. Kiela, C.Wang, and K. Cho, “Dynamic meta-embeddings for improved sentence representations,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 1466–1477, 2018.
[3] G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” in NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego California, USA, June 12-17, 2016, pp. 260–270, 2016.
[4] Y. Zhang and J. Yang, “Chinese NER using lattice LSTM,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pp. 1554–1564, 2018.
作者简介
张乃心,硕士在读,2017年由西安电子科技大学保送至中国科学院大学,研究方向为信息抽取。
作者:张乃心
编辑:王慎思

↓查看原论文


