刊首语这里记录ML自学者群体,每周优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「阅读原文」,才能访问文中的链接。
本期内容论文速递
?CVPR2019:细粒度图像识别新论文?基于元学习和AutoML的模型压缩新方法
学习心得
?大煌?奔腾?昨夜星辰?大灵?大鹏鹏?安芯?吕涛
疑问解答
?lstm激活函数为什么sigmoid和tanh同时存在?研究生阶段如何规划
论文速递CVPR2019:细粒度图像识别新论文论文名称:Destruction and Construction Learning for Fine-grained Image Recognition
论文地址[1]
该文献是属于细粒度图像识别领域的。文章提到部分先前的方法需要判别性区域的标注先验信息,标注成本高昂;并且先前方法一般需增加额外模块,而这些模块在推断阶段会引入额外的计算负担。
因此文章引入“拆解与建构学习”机制使分类模块获得专家知识,其中“拆解”部分强迫分类模块着重于判别性区域的区别,“建构”部分建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象。文章工作中包括性能对比、消融实验、控制变量法参数调整实验、特征可视化等。
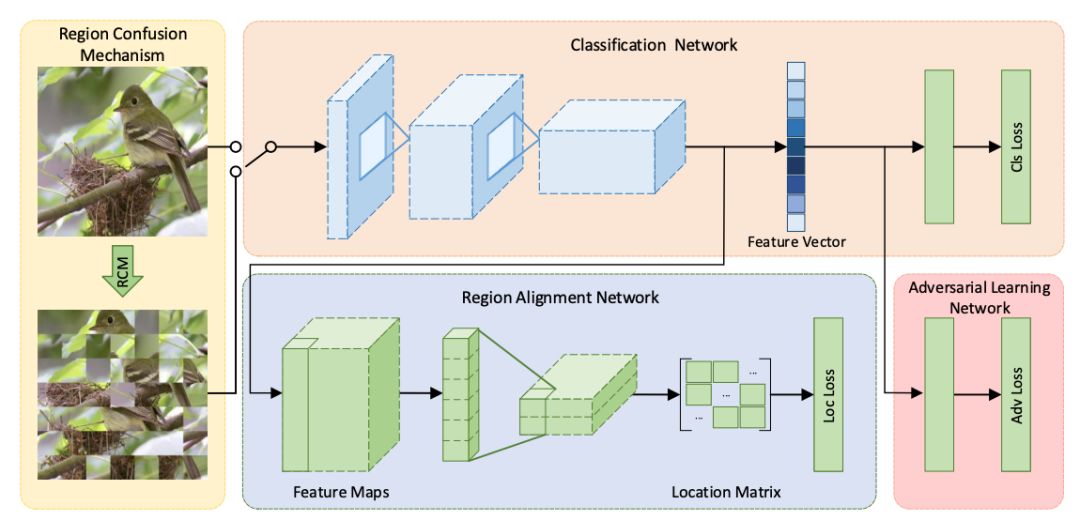
一句话概括该文献:引入“拆解与建构学习”机制,强迫分类模块着重于判别性区域的区别,并建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象,且未引入额外判别性区域标注负担和推断阶段的额外计算负担。
基于元学习和AutoML的模型压缩新方法这篇文章来自于旷视。旷视内部有一个基础模型组,孙剑老师也是很看好 NAS 相关的技术,相信这篇文章无论从学术上还是工程落地上都有可以让人借鉴的地方。回到文章本身,模型剪枝算法能够减少模型计算量,实现模型压缩和加速的目的,但是模型剪枝过程中确定剪枝比例等参数的过程实在让人头痛。
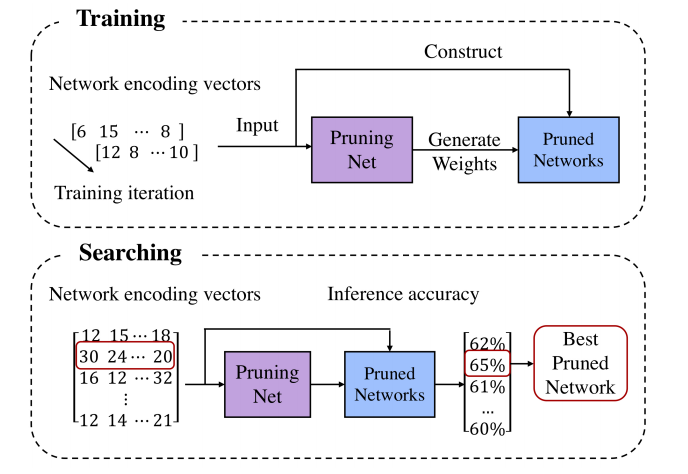
这篇文章提出了 PruningNet 的概念,自动为剪枝后的模型生成权重,从而绕过了费时的 retrain 步骤。并且能够和进化算法等搜索方法结合,通过搜索编码 network 的 coding vector,自动地根据所给约束搜索剪枝后的网络结构。和 AutoML 技术相比,这种方法并不是从头搜索,而是从已有的大模型出发,从而缩小了搜索空间,节省了搜索算力和时间。
论文地址[2] 原文地址
学习心得大煌本周复现了一篇论文的代码。复现的效果没有论文的好。是一个很基础的版本,欢迎交流和探讨。复现代码地址[3]
奔腾本周复习了一下概率论,具体是过了一遍叶丙成老师的玩想概率,相对国内过于注重计算,而叶老师的课程很注重概念。最简单的概念,随机变量到底是什么,如果这个不清楚的话,可以再认真学学概率,会有新的收获。
昨夜星辰本周学习了词向量的三种:word2vec,fasttext,elmo。代码如下,放在笔记里面:
?word2vec[4]?fasttext[5]?elmo[6]
大灵这周了解了一下密集计数。
?聚类计数:基于外观和运动线索等特征进行聚类,适用于视频序列,不适用于图象。缺点:需要视频,准确率较低?回归计数:通过检测计数 两种:一是使用计算对象的密度来预测密度图。使用高斯核将点级注释矩阵转换为密度图。挑战是确定高斯核的最佳大小,这个与对象的大小密切相关。第二种是一瞥(glance)基于网格的计数方法(不太懂) 缺点:受物体的大小变化影响大。 ?检测计数:先检测出对象,再计算数量,比glance和子图标的表现更差。缺点:如果对象被遮挡效果就不好,其实物体的大小对这个的影响也有,效果可能要看训练集和实际场景了。
大鹏鹏本周由于在赶论文,所以自学的不多,主要看了《大话数据结构》中的第三、四章节,以及《数学之美》中的前5章。这两本书算是入门类型的书籍了,根据之前看别人的经验帖子,前者适合刷题吃力的小伙伴看,或者适合作为入门自然语言处理的启蒙教材。
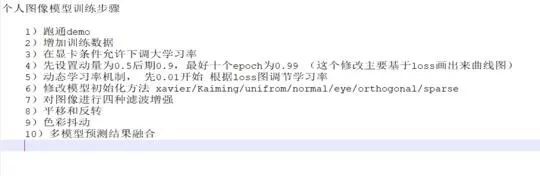
安芯最近对图像分析做了一个简单的小结,我个人把模型训练的相关流程简单的总结一下如下:个人研究loss和初始化对模型影响最大除模型结构之外。
吕涛本周刚开始接触机器学习,学习了贝叶斯,线性回归,决策树,KNN模型,模型的评价方法
1.贝叶斯模型是基于概率的,通过贝叶斯方程和模糊处理,将事件的概率约等于已发生概率的积。2.线性回归主要采用广度摸索和深度搜索方法,对已发生事件对应的线性函数进行最优求解3.决策树主要通过求解不同分割点得信息熵之和,判定每次的最优分割点,最终生成决策树。4.模型评价主要通过不同纬度来进行,需要视情况而定,如pression,recall,auc等等5.知道了过拟合是什么意思,导致它产生的原因有很多,如数据太少,模型太复杂,数据分布,模型变化太快等等
疑问解答lstm 激活函数为什么 sigmoid 和 tanh 同时存在[7]其中一个原因如下:输入x经过sigmoid函数后均值在0.5左右,不利于后续激活函数的处理。
而tanh的输出在[-1,1]之间,因此相当于把输入的均值调整为0,便于后续处理。
因此,tanh一般来说总是比sigmoid函数效果更好。
除了一些特殊情况:比如你想要激活函数的输出值是一个概率时,显然sigmoid函数更好。
研究生阶段如何规划老师,您好。我现在大四学生,现在已经推免,本科和硕士专业为GIS(地理信息系统)。据我了解硕士老板是个大牛,但是其方向主要是系统应用开发,但我对数据科学这块比较感兴趣,将来也有读博打算,因为前期参加比赛和论文写作,对数据科学方面有一点了解,现在在系统的学着机器学习,请问研究生阶段该如何规划呢?
你这个问题首先存在以下方面考虑:
?第一:你是否真心喜欢你所在领域,能坚持研究几年。?第二:你老板很牛是老板很牛,他只能会在你发论文和申请项目及开题帮助较大,写代码和推公式等活没人帮你干只有自己。?第三:你已经推免说明成绩在前十自己自学能力ok这点自信还是要有,自信、多尝试、坚持是做好的思想基础。系统开发和数据科学不冲突,数据科学只是系统开发一部分。GIS这个方向挺好可以做交通也可以搞地理和其他用途很广。?第四:作为一名研究生快速成长的方式是完成自己科研任务同时选择学术方向还是工程方向的决定后再开始深入的做下去。?第五:根据我的了解报送学生时间相对宽裕,我的建议第一年针对GIS方向完成毕业指标论文和三个大数据比赛并获奖及自己的研究生课程。第二年完成自己的系统及开发。第三年尽量在实习前做出整个基于机器学习的系统开发demo。
总结:以上的建议仅仅代表个人看法,这样做的好处
?能顺利工作和读博二选一都不影响。?前一两年做好的数学基础在系统开发应用起来可以提高开发效率。?面试的时候如果达到以上的水平根据我对各大公司和单位的可以直接拿到ssp的提前批免得进入费力的系统面试阶段。
加入我们公众号内回复「自学」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者优质学习资料,助力团体共同学习进步。

上一期内容References[1] 论文地址: http://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf
[2] 论文地址: https://arxiv.org/abs/1903.10258
[3] 复现代码地址: https://github.com/HaHuangChan/Deep-Mating-for-Portrait-Animation
[4] word2vec: https://blog.csdn.net/weixin_43178406/article/details/102461021
[5] fasttext: https://blog.csdn.net/weixin_43178406/article/details/102465629
[6] elmo: https://blog.csdn.net/weixin_43178406/article/details/102522853
[7] lstm 激活函数为什么 sigmoid 和 tanh 同时存在: https://www.zhihu.com/question/46197687/answer/229098444

关于本站

“机器学习初学者”公众号由是黄海广博士创建,黄博个人知乎粉丝22000+,github排名全球前110名(32000+)。本公众号致力于人工智能方向的科普性文章,为初学者提供学习路线和基础资料。原创作品有:吴恩达机器学习个人笔记、吴恩达深度学习笔记等。
往期精彩回顾
那些年做的学术公益-你不是一个人在战斗
适合初学者入门人工智能的路线及资料下载
吴恩达机器学习课程笔记及资源(github标星12000+,提供百度云镜像)
吴恩达深度学习笔记及视频等资源(github标星8500+,提供百度云镜像)
《统计学习方法》的python代码实现(github标星7200+)
精心整理和翻译的机器学习的相关数学资料首发:深度学习入门宝典-《python深度学习》原文代码中文注释版及电子书
备注:加入本站微信群或者qq群,请回复“加群”加入知识星球(4300+用户,ID:92416895),请回复“知识星球”


